














简介
在当今数字时代,数据对于组织的成功至关重要。数据保护和高可用性是确保数据完整性和系统可用性的关键因素,从而使组织能够连续运营并避免潜在的损失。
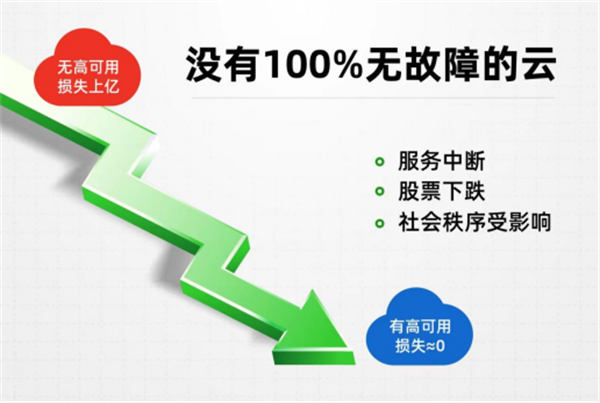
高可用性:避免停机
高可用性通过确保系统即使在遇到故障的情况下也能持续运行来提高可用性。这需要冗余基础设施、故障转移机制和持续监控,以检测并快速解决问题。
- 冗余
安全架构的设计原则:如何构建高度可扩展的安全系统
随着互联网的迅速发展,我们的生活和工作越来越依赖于计算机系统和网络。
然而,这也意味着我们的系统和网络正面临越来越多的安全威胁。
因此,构建高度可扩展的安全系统已成为一项至关重要的技术。
本文将探讨如何构建此类系统,并介绍一系列设计原则和实践方法。
在构建安全系统时,我们需要考虑的关键概念包括安全性、可扩展性、可靠性、可用性、可维护性、可测试性、可恢复性和可伸缩性。
这些概念之间紧密相连,构建安全系统时必须充分考虑它们。
安全性是计算机系统和网络的基本要求。
它包括保护数据的机密性、完整性和可用性。
实现安全性需要采用加密算法、身份验证机制、授权机制和安全策略等手段。
可扩展性是指系统的能力,能根据需求增加资源,以应对更大的用户量和更复杂的应用场景。
实现可扩展性通常依赖于分布式系统、负载均衡、缓存和并行计算等技术。
可靠性是指系统在给定时间内保持预期性能和较低故障率的能力。
可靠性实现通常涉及冗余设备、错误检测与恢复机制、故障预防和隔离等技术。
可用性则指系统在指定时间内提供预期服务的能力。
实现可用性通常包括高可用性设计、负载均衡、容错机制和故障恢复等措施。
可维护性指的是系统在指定时间内进行修改和更新的能力。
可维护性实现通常涉及模块化设计、代码规范、文档记录和测试驱动开发等技术。
可测试性则是指系统在指定时间内进行测试和验证的能力。
实现可测试性通常依赖于测试驱动开发、自动化测试、测试覆盖和测试驱动设计等方法。
可恢复性指的是系统在发生故障时恢复到正常状态的能力。
实现可恢复性通常涉及备份和恢复策略、故障恢复机制和错误日志等技术。
可伸缩性是指系统在给定时间内根据需求增加资源的能力。
实现可伸缩性通常使用分布式系统、负载均衡、缓存和并行计算等技术。
为了实现上述安全架构设计原则,我们需要使用算法和技术手段,如加密算法、身份验证机制、授权机制、安全策略、分布式系统、负载均衡、缓存、并行计算、冗余设备、错误检测和恢复机制、故障预防和故障隔离等。
在具体实现时,我们将使用Python语言编写代码,并通过实例来说明如何实现这些设计原则。
例如,我们将展示如何使用AES加密算法对数据进行加密和解密,如何使用密码验证进行身份验证,如何使用基于角色的访问控制(RBAC)实现授权机制,以及如何使用访问控制策略实现安全策略。
为了实现分布式系统,我们将使用Python的multiprocessing库。
负载均衡将通过使用requests库的Session类来实现。
缓存实现则通过使用cachelib库的LRUCache类。
并行计算通过库的ThreadPoolExecutor类来实现。
冗余设备、错误检测和恢复机制、故障预防和故障隔离等技术,将分别通过相应的算法和策略实现。
综上所述,构建高度可扩展的安全系统是一个复杂而细致的过程,涉及到多个关键概念和技术手段。
通过遵循上述设计原则并实施具体代码实例,我们可以有效地构建出安全、可扩展、可靠的系统。
分布式数据库系统由什么组成?
分布式数据库系统主要由分布于多个计算机结点上的若干个数据库系统组成。
这些数据库系统在不同的结点上协同工作,通过网络进行数据共享与交互。
分布式数据库系统旨在利用多台计算机的资源,实现数据的高可用性和高可扩展性。
在分布式数据库系统中,每个结点上的数据库系统通常称为子数据库。
这些子数据库可以存储相同数据的不同部分,以实现数据的冗余和分布存储。
这样,即使某个结点出现故障,系统仍然可以从其他结点上恢复所需数据。
为了确保数据的一致性和完整性,分布式数据库系统通常采用分布式事务处理机制。
这些机制确保在多个结点上执行的事务操作能够按照预定的规则进行,从而保证数据在不同结点之间的一致性。
此外,分布式数据库系统还需要支持数据复制和同步功能。
通过定期或实时地同步子数据库之间的数据,确保各个结点上的数据保持一致。
这种数据复制和同步机制有助于提高系统的数据可用性和容错能力。
在分布式数据库系统中,还存在一些关键组件和功能,如负载均衡、故障恢复、复制策略、查询优化和数据一致性维护等。
这些组件和功能共同协作,以提高系统的性能、可靠性和数据管理能力。
总之,分布式数据库系统由分布于多个计算机结点上的若干个数据库系统组成,这些系统通过网络进行数据共享与交互,实现高效的数据存取和处理。
通过采用分布式事务处理机制、数据复制和同步功能,以及各种关键组件和功能,分布式数据库系统能够提供高可用性、高可扩展性和高效的数据管理。
分布式数据库特点
分布式数据库是一种将数据分散存储在多个数据库实例或服务器上的数据库系统。它具有以下特点:
数据分布性:分布式数据库的数据分散存储在多个数据库实例或服务器上,每个实例或服务器存储一部分数据,从而提高了数据的安全性和可用性。
数据一致性:分布式数据库中的数据是一致的,即多个数据库实例或服务器之间的数据是同步的,保证了数据的完整性和一致性。
可扩展性:分布式数据库可以轻松地扩展,只需添加新的数据库实例或服务器即可,从而提高了系统的可扩展性和灵活性。
高可用性:分布式数据库可以自动容错和恢复,当某个数据库实例或服务器出现故障时,系统可以自动切换到其他可用的实例或服务器,从而提高了系统的可用性和可靠性。
灵活性:分布式数据库可以灵活地适应不同的应用场景,可以支持不同的业务需求,从而提高了系统的灵活性和适应性。
总之,分布式数据库是一种高效、可靠、可扩展的数据库系统,它具有很多优点,如高可用性、可扩展性、灵活性等,能够满足不同应用场景的需求。







