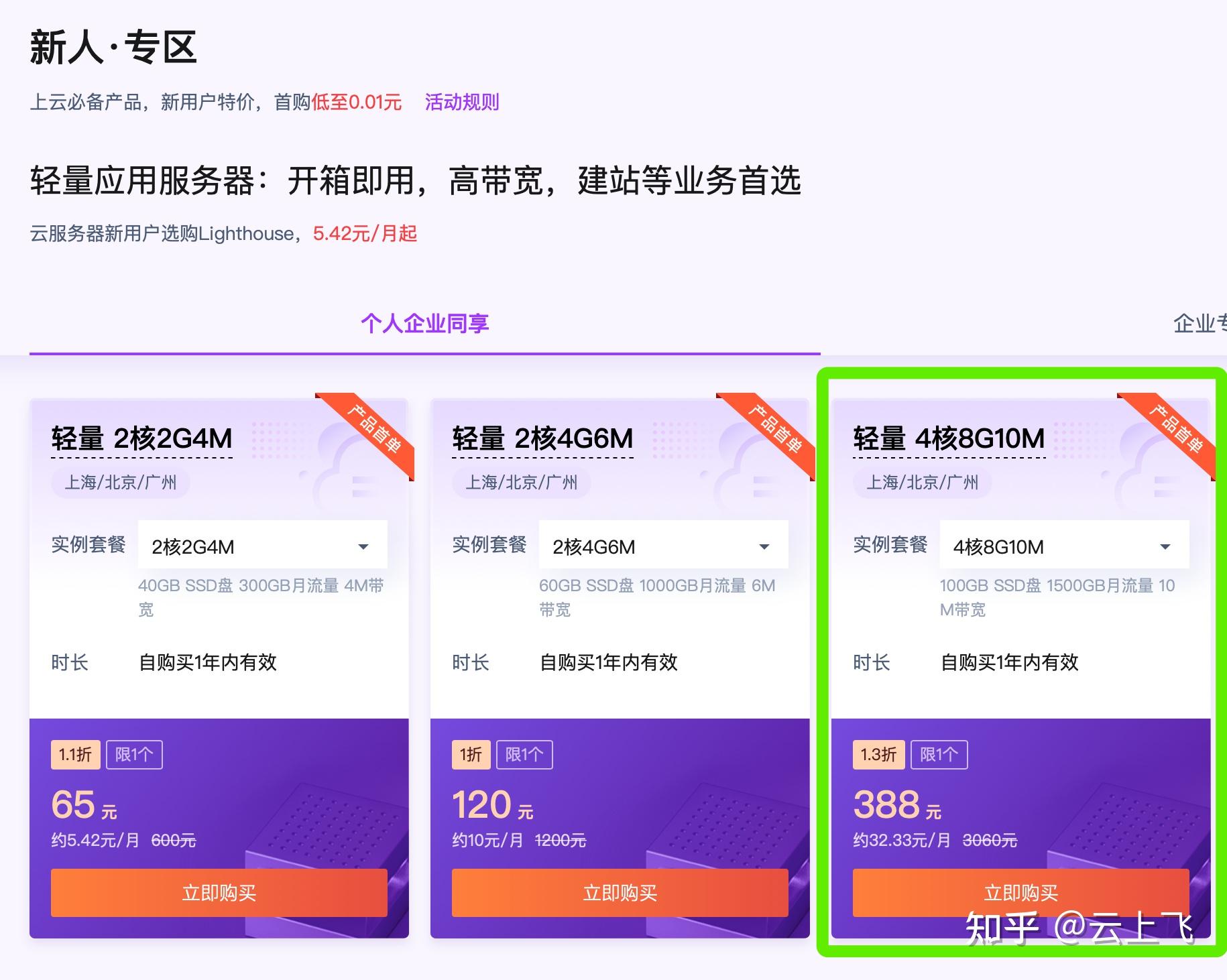
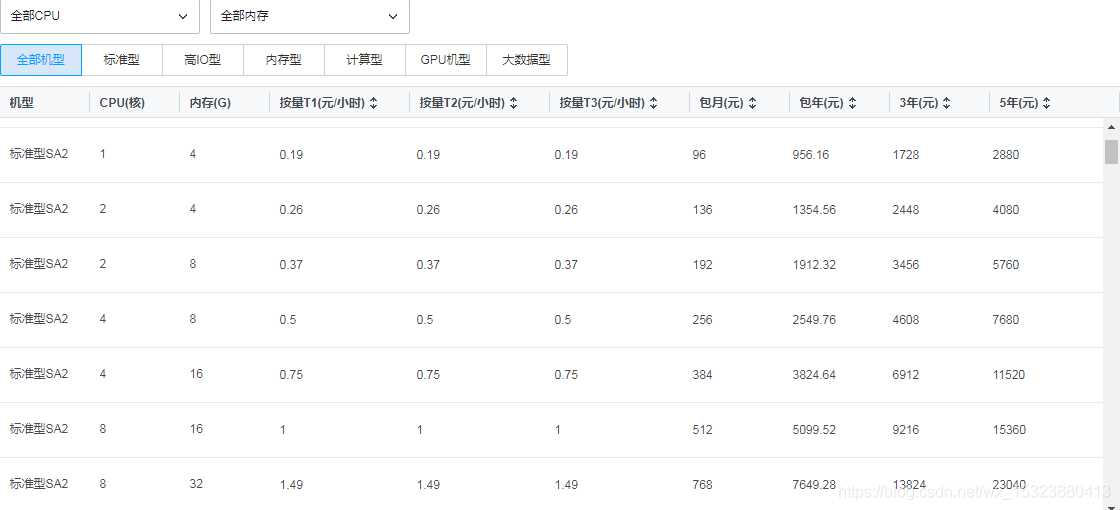
深度解读百度的数据处理能力:多少台服务器在后台支撑其高效运作?

一、引言
随着互联网技术的飞速发展,搜索引擎已成为人们获取信息的主要途径之一。
在众多搜索引擎中,百度以其强大的数据处理能力脱颖而出,为广大用户提供了高效、精准的搜索服务。
那么,究竟是怎样的后台技术架构和多少台服务器在支撑百度的高效运作呢?本文将带您深度解读百度的数据处理能力。
二、百度数据处理能力的核心
1. 数据采集
百度数据处理能力的核心在于其强大的数据采集能力。
百度通过爬虫技术,不断地从互联网上抓取海量的网页信息,并对这些网页进行索引。
百度还通过用户行为数据、社交数据等多种数据来源,收集各种结构化、非结构化数据,为后续的搜索、推荐等服务提供数据支持。
2. 数据处理
采集到的数据需要经过一系列的处理过程,才能为用户提供有价值的搜索服务。
百度采用分布式计算框架,对海量数据进行高效处理。
这些处理过程包括文本分析、语义理解、数据挖掘等,以便更好地满足用户的搜索需求。
3. 数据存储
处理后的数据需要存储起来,以便用户进行检索。
百度采用分布式存储技术,将数据存储在不同的服务器上,实现数据的快速访问。
同时,百度还通过数据压缩、数据备份等技术手段,确保数据的可靠性和安全性。
三、百度后台技术架构
为了支撑上述数据处理过程,百度构建了一套庞大的后台技术架构。这个架构包括以下几个部分:
1. 云计算平台
百度拥有一个强大的云计算平台,为数据处理提供强大的计算资源。
云计算平台可以动态地分配计算资源,以满足不同业务的需求。
2. 分布式存储系统
百度采用分布式存储系统,将数据存储在不同的服务器上,实现数据的快速访问。
同时,分布式存储系统还可以提高数据的可靠性和安全性。
3. 大规模分布式计算集群
百度拥有一个庞大的分布式计算集群,包括数十万台服务器。
这些服务器通过高速网络相互连接,共同处理海量的数据任务。
4. 智能化算法模型
为了更好地满足用户需求,百度不断研发新的算法模型,如深度学习、机器学习等。
这些算法模型可以帮助百度更好地理解用户意图,提高搜索结果的精准度。
四、多少台服务器在支撑百度的高效运作?
那么,究竟有多少台服务器在支撑百度的高效运作呢?根据公开资料,百度的服务器规模已经超过了数十万台。
这些服务器分布在全球各地,共同为百度提供强大的计算能力和存储能力。
为了应对不断增长的数据量和服务需求,百度还在不断扩充其服务器规模。
五、结语
百度的数据处理能力得益于其强大的后台技术架构和庞大的服务器规模。
数十万台服务器分布在全球各地,共同为百度提供强大的计算能力和存储能力。
未来,随着技术的不断发展,百度将继续优化其技术架构,提高数据处理能力,为广大用户提供更加高效、精准的搜索服务。
同时,百度还将不断探索新的技术领域,如人工智能、大数据等,以不断提升自身的核心竞争力。